Kafka常见面试题及简要解答(上篇)
这段时间京东的技术类书各种满多少减多少,小组老司机说这个月的活动经费不吃饭了,买书吧!
鞥。。。实在是我的书太多了,经典的书基本上都买了,不知道我还能买些什么。。。
不过有句话说的好:书非借不能读也!我的书基本上在吃灰。
不过最后还是买了两本:《Rust编程之道》、《深入理解Kafka核心设计与实践原理》。前者暂时不表,之所以买后者呢,是因为一直也没深入学过Kafka,关注过后者的作者的微信公众号,前段时间推了一篇Kafka面试题全套整理 | 划重点要考!,看了里面的题目,感觉一脸懵逼,既然他又写了本书,那就买来看看吧。。。
啰嗦了这么多,开始正题吧,接下来我将会把文章里面所列出的题目都一一简要作答,以供参考。
Kafka的用途有哪些?使用场景如何?
消息系统:可以当做传统消息中间件,并且提供了大多数消息系统难以实现的消息顺序性保障及回溯消息功能。
存储系统:Kafka的消息持久化到硬盘进行存储,并且是多副本存储。我们可以设置数据保留策略为”永久”来作为长期数据存储系统来使用。
流处理平台:Kafka提供了一个完整流式处理类库,比如窗口,连接,变换和聚合等操作。
Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么?
ISR(In-Sync Replicas):所有与leader副本保持一定程度同步的副本组成ISR,ISR集合是AR集合中的一个子集。
AR(Assigned Replicas):分区中所有副本系统的成为AR。
ISR的伸缩:leader副本负责维护与跟踪ISR集合中所有follower副本的滞后程度,当follower副本落后太多或者失效是,leader副本会将他从ISR集合中剔除并加入OSR中,如果OSR集合中有follower副本”追上”了leader副本,那么leader副本会把它从OSR集合中转移到ISR集合。
一定程度同步:Kafka消息生产者发送的消息首先会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间follower副本相对于leader副本会有一定程度的之后,而这个滞后返回可以通过参数配置。而滞后超过这个配置的则组成OSR(Out-of-Sync Replicas)
Kafka中的HW、LEO、LSO、LW等分别代表什么?
HW(High Watermark):俗称高水位,它标识一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。
LEO(Log End Offset):它标识当前日志文件中下一条代写入消息的offset,相当于当前日志分区中最后一条消息的offset+1,分区ISR集合中每个副本都会维护自身的LEO,而ISR集合中最小的LEO及为分区的HW,而消费者也只能消费HW之前的消息。
Kafka中是怎么体现消息顺序性的?
Kafka的消息有序通过offset提现,offset是消息在分区中的唯一标识,Kafka通过offset保证消息在分区内的有序性,但是offset不能跨越分区,所以Kafka的消息有序性只体现在分区有序而不是主题有序。
Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
分区器:计算消息即将发送到的分区号,Kafka提供了默认的分区器,分区规则:如果消息的key不为null,那么对key进行hash(使用MurmurHash2算法,具备高性能及低碰撞率),根据最终得到的hash值来计算分区号;若key为null,那么消息将会Yui轮询的方式发送到主题内的各个可用分区。
序列化器:生产者需要序列化器将对象序列化字节数组才能通过网络发送给Kafka,而消费者需要反序列化器把从Kafka中接收到的字节数组转换成对应的对象。
处理顺序:拦截器->序列化器->分区器。
Kafka生产者客户端的整体结构是什么样子的?
Kafka生产者客户端整体架构简要概述:整个生产者客户端由两个线程协调运行,分别为主线程和Sender线程,主线程中油KafkaProducer创建消息,然后通过拦截器->序列化器->分区器的处理之后交给消息累加器(RecordAccumulator,也称为消息收集器),Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
Kafka生产者客户端中使用了几个线程来处理?分别是什么?
两个线程(其实应该算一个,调用send的那个线程照理来说不属于Kafka客户端),业务线程调用KafkaProducer.send()方法,发送消息,经过拦截器->序列化器->分区器之后,将消息交给RecordAccumulator,Sender线程负责将消息发送到Kafka中。
Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
工作状态不明确:旧版消费者基于Zookeeper的Watcher来实现功能,每个消费者对相关的路径进行监听,当触发再均衡操作时,一个消费者组下的所有消费者会同时进行在均衡操作,而消费者之间并不知道彼此操作的结果,可能会导致Kafka工作在一个不正确的状态。
过度依赖Zookeeper集群:
- 羊群效应:Zookeeper中一个被监听的节点变化,大量的Watcher事件通知被发送到客户端,导致在通知期间的其他操作延迟,也可能发生死锁问题。
- 脑裂问题:消费者再均衡操作时,每个消费者都与Zookeeper进行通信以判断消费者或Broker变化的情况,由于Zookeeper本身的特性,可能导致同一时刻的消费者获取的状态不一致。
“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?
不正确。
自定义分区分配策略使一个分区可以分配给多个消费者消费(具体实现可以单独写一篇文章,这里就不再进行详细的叙述了)。
消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
当前消费者需要提交的offset并不是offset,而是offset+1,它标识下一条需要拉取消息的位置
有哪些情形会造成重复消费?
一次拉取多条消息,消息全部处理完成再进行位移提交。若消费者在处理了部分消息之后异常宕机,则此时没有进行位移提交,故障恢复后消费者再次拉取的消息还是从宕机前最后一次提交的offset开始。此为重复消费消息。
那些情景下会造成消息漏消费?
一次拉取多条消息,拉取消息之后马上进行了位移提交。消费者在处理了部分消息之后异常宕机,故障恢复之后拉取到的是已经位移提交之后的值,未处理的消息则被漏消费(漏处理)。
KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
如何实现多线程消费:
- 每一个消费线程单独持有一个KafkaConsumer对象,但是此方法线程数受限于分区的实际个数。
- 多个线程消费同一个分区,实现复杂,不推荐。
- 单线程接收消息,多线程处理消息,但此方法会导致消息无法顺序处理,手动位移提交需要特别设计。
KafkaConsumer定义了一个acquire方法,用来检查当前是否只有一个线程在操作,若有其他线程正在操作此KafkaConsumer,则会抛出ConcurrentModifcationException异常,其实现方式也异常简单,节选代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// currentThread holds the threadId of the current thread accessing KafkaConsumer
// and is used to prevent multi-threaded access
private static final long NO_CURRENT_THREAD = -1L;
private final AtomicLong currentThread = new AtomicLong(NO_CURRENT_THREAD);
/**
*
* 获取一个轻量级锁用来保证消费者在多线程下是线程安全的,如果锁已经被其他线程持有了则抛出 ConcurrentModificationException。
* 而这个锁的获取也挺简单,currentThread默认值为NO_CURRENT_THREAD,通过cas设置当前线程的值,若设置失败,则代表有其他线程已经在操作此KafkaConsumer,则抛出异常。
*/
private void acquire() {
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId)) {
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access");
}
// 此处代表这个锁也是可重入的。
refcount.incrementAndGet();
}
/**
* 示范锁,当refcount减至0,则代表当前线程不再持有此KafkaConsumer
*/
private void release() {
if (refcount.decrementAndGet() == 0)
currentThread.set(NO_CURRENT_THREAD);
}简述消费者与消费组之间的关系。
若所有的消费者都属于同一个消费组,那么所有的消息都会被均衡的投递给每一个消费者,即每条消息知会被一个消费者处理,这就相当于“点对点”模式的应用
若所有的消费者都隶属于不同的消费组,那么所有的消息都会被广播给所有的消费者,即每条消息都会被所有的消费者处理,这就相当于“发布/订阅”模式的应用
当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
创建topic:Kafka在log.dir或者log.dirs参数所配置的目录下创建相应的主题分区,在zookeeper中创建/brokers/topics/{topic-name}、/config/topics/{topic-name}节点。
删除topic:删除Zookeeper中/config/topics/{topic-name}节点、删除/brokers/topics/{topic-name}几点及其子节点,删除Kafka集群中在log.dir或者log.dirs参数所配置的目录下所有与主题{topic-name}相关的文件。
topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
分区数可以增加。
通过topic-config.sh脚本中的alter命令进行分区增加操作。
topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不支持分区数减少。
删除分区会引起一系列问题,比如消息的顺序性、事务性、以及分区和副本的状态机切换问题。
创建topic时如何选择合适的分区数?
分区数的选择视具体情况而定。
增加合适的分区数可以在一定程度上提升整体的吞吐量,但超过对应的阈值之后吞吐量不升反降,建议在生成环境中做一个完备的测试找到合适分区数与阈值。
Kafka目前有那些内部topic,它们都有什么特征?各自的作用又是什么?
截止至Kafka 2.0.0版本,Kafka内部保护两个主题:__consumer_offsets、__transaction_state
__consumer_offsets用于存放存放消费者偏移量,__transcation_state用于持久化事务状态信息。
优先副本是什么?它有什么特殊的作用?
优先副本是指在AR集合列表中第一个副本。
理想情况下,优先副本就是该分区的leader副本,Kafka会确保所有的主题的优先副本在集群中均匀分布
Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理。
这题不太明白具体意思,到底是说Kafka的创建主题之后的brokers的分区分配,还是分区重分配的分区分配,还是消费者的分区分配。。。
暂且放这里。。。
简述Kafka的日志目录结构。
大致目录结构如下
此处应当有图
/{kafka-logs}/{topic-name}-{partition}/{index,log,timeindex}
Kafka中有那些索引文件?
有偏移量所有文件*.index和时间索引文件*.timeindex。
如果我指定了一个offset,Kafka怎么查找到对应的消息?
Kafka中的索引文件是稀疏索引,并不保证每个消息在索引文件中都有对应的索引项,offset索引文件是单调递增的,查询指定offset时,使用二分查找法来快速定位offset的位置,如果指定的offset不在索引文件中,则会返回喜爱与指定offset的最大offset。
如果我指定了一个timestamp,Kafka怎么查找到对应的消息?
timestamp的索引文件也保持严格的单调递增,同样使用二分查找法找到此timestamp对应的offset,再根据此offset去查找offset的索引文件再次定位。
聊一聊你对Kafka的Log Retention的理解。
按照一定的保留策略直接删除不符合条件的日志分段。
主要分为下面三种策略:
- 基于时间:日志删除任务会检查当前日志文件中是否有保留时间超过设定阈值的日志分段文件集合。阈值可以通过broker端参数
log.retention.hours、log.retention.minutes和log.retention.ms来配置,优先级依次提高。默认情况只配置了log.retention.hours参数,其值为168,即日志分段文件的默认保留时间为7天。 - 基于日志大小:日志删除任务会检查当前日志文件中是否有文件大小超过设定阈值的日志分段文件集合。阈值可以通过broker端参数
log.retention.bytes(此配置是Log中所有的日志文件的总大小)来配置,默认值为-1,表示无穷大;单个日志分段大小的配置为log.segment.bytes来限制,默认值为1073741824,即为1GB - 基于日志起始偏移量:基于日志起始偏移量的保留策略的判断依据是某日志分段的下一个日志分段的起始偏移量
baseOffset是否小于logStartOffset,若是则可以删除此日志分段。
- 基于时间:日志删除任务会检查当前日志文件中是否有保留时间超过设定阈值的日志分段文件集合。阈值可以通过broker端参数
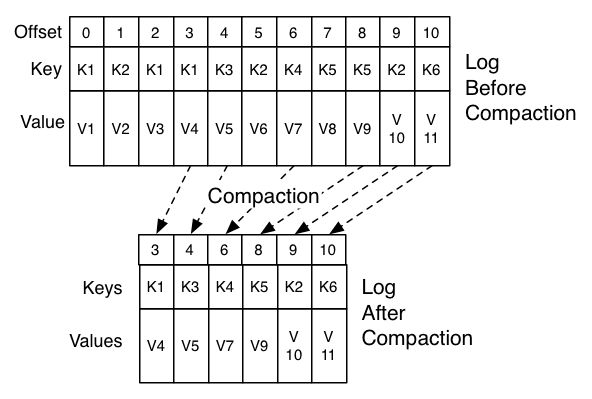
聊一聊你对Kafka的Log Compaction的理解
针对每个消息的key进行整合,对于有相同的key,不同value值,只保留最后一个版本,下图为官方示意图(也可以新开一章详细叙述)
以上是部分面试题的简要解答,若有疏漏与错误之处还请谅解与指出,不胜感激。
下篇再见。。。